publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2026
- EGSR
 ResEdit: Residual Embeddings for Precise Generative Image EditingAhmet Canberk Baykal, Valentin Deschaintre, Yannick Hold-Geoffroy, Michael Fischer, Anna Frühstück, Cengiz Öztireli, and Iliyan GeorgievIn Eurographics Symposium on Rendering (EGSR), 2026
ResEdit: Residual Embeddings for Precise Generative Image EditingAhmet Canberk Baykal, Valentin Deschaintre, Yannick Hold-Geoffroy, Michael Fischer, Anna Frühstück, Cengiz Öztireli, and Iliyan GeorgievIn Eurographics Symposium on Rendering (EGSR), 2026Conditional diffusion image generators can be repurposed for editing through inversion, without the need for large-scale paired fine-tuning data. However, producing high-quality, targeted edits while maintaining image identity and global consistency remains challenging, as weakly conditioned inversion often embeds conflicting image features into the noise. We demonstrate that incorporating a residual image encoding as additional conditioning enables both improved identity preservation and better editability. We optimize this residual encoding to provide a strong conditioning signal for reconstruction, thereby reducing the reliance on inversion and susceptibility to its aforementioned pitfalls. To ensure this residual does not interfere with desired edits, we incorporate a gradient reversal-based optimization strategy that disentangles the residual from the edited condition. We illustrate our method’s ability to produce high-fidelity results across precise intrinsic-based editing and relighting, and show proof-of-concept text-guided manipulation.
@inproceedings{baykal2026resedit, title = {ResEdit: Residual Embeddings for Precise Generative Image Editing}, author = {Baykal, Ahmet Canberk and Deschaintre, Valentin and Hold-Geoffroy, Yannick and Fischer, Michael and Fr{\"u}hst{\"u}ck, Anna and {\"O}ztireli, Cengiz and Georgiev, Iliyan}, booktitle = {Eurographics Symposium on Rendering (EGSR)}, year = {2026}, } - ICLR
 Quartet of Diffusions: Structure-Aware Point Cloud Generation through Part and Symmetry GuidanceChenliang Zhou, Fangcheng Zhong, Weihao Xia, Albert Miao, Canberk Baykal, and Cengiz OztireliIn Proceedings of the International Conference on Learning Representations (ICLR), 2026
Quartet of Diffusions: Structure-Aware Point Cloud Generation through Part and Symmetry GuidanceChenliang Zhou, Fangcheng Zhong, Weihao Xia, Albert Miao, Canberk Baykal, and Cengiz OztireliIn Proceedings of the International Conference on Learning Representations (ICLR), 2026We introduce the Quartet of Diffusions, a structure-aware point cloud generation framework that explicitly models part composition and symmetry. Unlike prior methods that treat shape generation as a holistic process or only support part composition, our approach leverages four coordinated diffusion models to learn distributions of global shape latents, symmetries, semantic parts, and their spatial assembly. This structured pipeline ensures guaranteed symmetry, coherent part placement, and diverse, high-quality outputs. By disentangling the generative process into interpretable components, our method supports fine-grained control over shape attributes, enabling targeted manipulation of individual parts while preserving global consistency. A central global latent further reinforces structural coherence across assembled parts. Our experiments show that the Quartet achieves state-of-the-art performance. To our best knowledge, this is the first 3D point cloud generation framework that fully integrates and enforces both symmetry and part priors throughout the generative process.
@inproceedings{zhou2026quartet, title = {Quartet of Diffusions: Structure-Aware Point Cloud Generation through Part and Symmetry Guidance}, author = {Zhou, Chenliang and Zhong, Fangcheng and Xia, Weihao and Miao, Albert and Baykal, Canberk and Oztireli, Cengiz}, booktitle = {Proceedings of the International Conference on Learning Representations (ICLR)}, year = {2026}, }
2024
- SIGGRAPH Asia
 HyperGAN-CLIP: A Unified Framework for Domain Adaptation, Image Synthesis and ManipulationAbdul Basit Anees, Ahmet Canberk Baykal, Muhammed Burak Kizil, Duygu Ceylan, Erkut Erdem, and Aykut ErdemIn SIGGRAPH Asia 2024 Conference Papers, 2024
HyperGAN-CLIP: A Unified Framework for Domain Adaptation, Image Synthesis and ManipulationAbdul Basit Anees, Ahmet Canberk Baykal, Muhammed Burak Kizil, Duygu Ceylan, Erkut Erdem, and Aykut ErdemIn SIGGRAPH Asia 2024 Conference Papers, 2024Generative Adversarial Networks (GANs), particularly StyleGAN and its variants, have demonstrated remarkable capabilities in generating highly realistic images. Despite their success, adapting these models to diverse tasks such as domain adaptation, reference-guided synthesis, and text-guided manipulation with limited training data remains challenging. Towards this end, in this study, we present a novel framework that significantly extends the capabilities of a pre-trained StyleGAN by integrating CLIP space via hypernetworks. This integration allows dynamic adaptation of StyleGAN to new domains defined by reference images or textual descriptions. Additionally, we introduce a CLIP-guided discriminator that enhances the alignment between generated images and target domains, ensuring superior image quality. Our approach demonstrates unprecedented flexibility, enabling textguided image manipulation without the need for text-specific training data and facilitating seamless style transfer. Comprehensive qualitative and quantitative evaluations confirm the robustness and superior performance of our framework compared to existing methods.
@inproceedings{anees2024hyperganclip, title = {{HyperGAN-CLIP}: A Unified Framework for Domain Adaptation, Image Synthesis and Manipulation}, author = {Anees, Abdul Basit and Baykal, Ahmet Canberk and Kizil, Muhammed Burak and Ceylan, Duygu and Erdem, Erkut and Erdem, Aykut}, booktitle = {SIGGRAPH Asia 2024 Conference Papers}, year = {2024}, doi = {10.1145/3680528.3687613}, }
2023
- ACM TOG
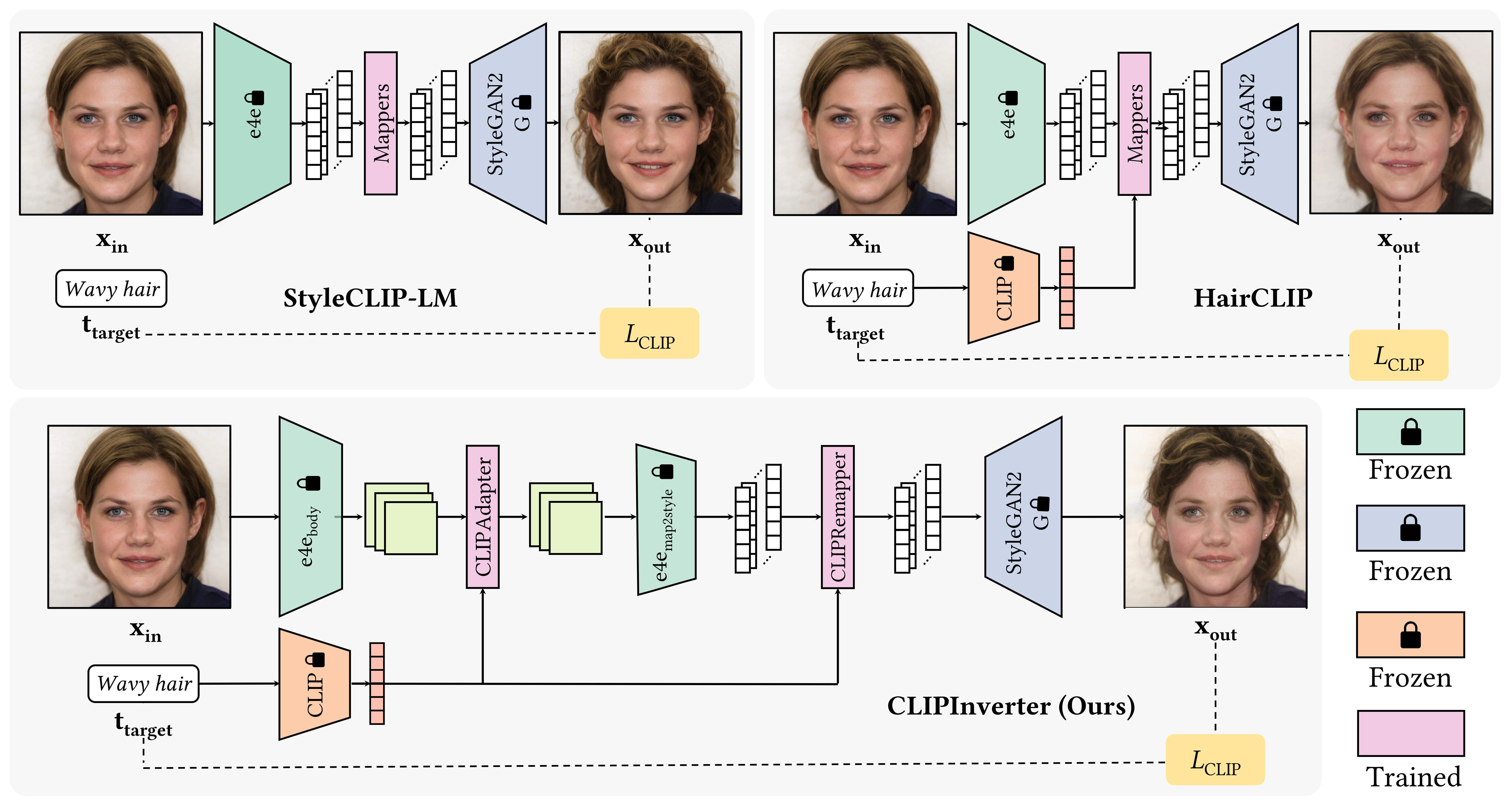 CLIP-Guided StyleGAN Inversion for Text-Driven Real Image EditingAhmet Canberk Baykal, Abdul Basit Anees, Duygu Ceylan, Erkut Erdem, Aykut Erdem, and Deniz YuretACM Transactions on Graphics, 2023Presented at SIGGRAPH Asia 2023
CLIP-Guided StyleGAN Inversion for Text-Driven Real Image EditingAhmet Canberk Baykal, Abdul Basit Anees, Duygu Ceylan, Erkut Erdem, Aykut Erdem, and Deniz YuretACM Transactions on Graphics, 2023Presented at SIGGRAPH Asia 2023Researchers have recently begun exploring the use of StyleGAN-based models for real image editing. One particularly interesting application is using natural language descriptions to guide the editing process. Existing approaches for editing images using language either resort to instance-level latent code optimization or map predefined text prompts to some editing directions in the latent space. However, these approaches have inherent limitations. The former is not very efficient, while the latter often struggles to effectively handle multi-attribute changes. To address these weaknesses, we present CLIPInverter, a new text-driven image editing approach that is able to efficiently and reliably perform multi-attribute changes. The core of our method is the use of novel, lightweight text-conditioned adapter layers integrated into pretrained GAN-inversion networks. We demonstrate that by conditioning the initial inversion step on the Contrastive Language-Image Pre-training (CLIP) embedding of the target description, we are able to obtain more successful edit directions. Additionally, we use a CLIP-guided refinement step to make corrections in the resulting residual latent codes, which further improves the alignment with the text prompt. Our method outperforms competing approaches in terms of manipulation accuracy and photo-realism on various domains including human faces, cats, and birds, as shown by our qualitative and quantitative results.
@article{baykal2023clipinverter, title = {{CLIP}-Guided {StyleGAN} Inversion for Text-Driven Real Image Editing}, author = {Baykal, Ahmet Canberk and Anees, Abdul Basit and Ceylan, Duygu and Erdem, Erkut and Erdem, Aykut and Yuret, Deniz}, journal = {ACM Transactions on Graphics}, year = {2023}, note = {Presented at SIGGRAPH Asia 2023}, doi = {10.1145/3610287}, }